
当前页为旧版本,仅维护, 新客户禁止使用。请使用新版DB连接器,2.x 版本!DB连接器2.x操作手册
一、部署说明
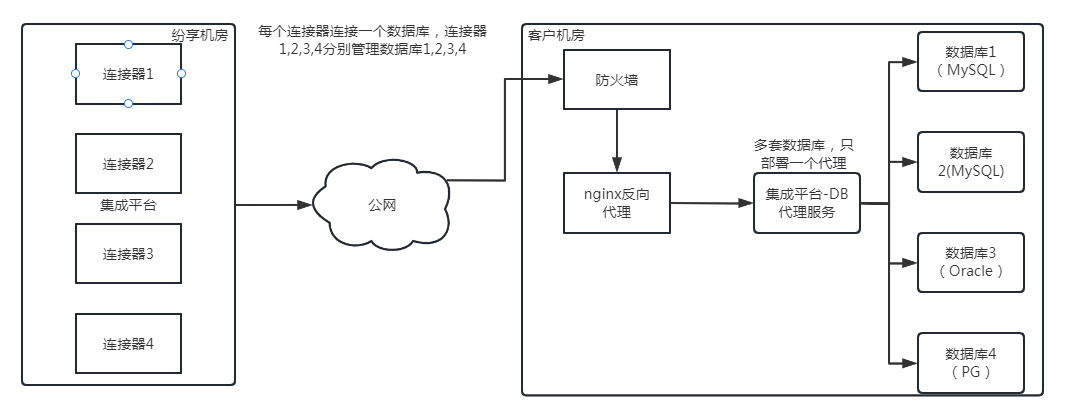
每个连接器,链接客户方的一个数据库。在客户方机房,只需要部署一个集成平台代理服务,就可以管理多个数据库。
集成平台使用管理员设置的代理服务账号密码访问DB代理服务,DB代理服务使用 数据库账号访问实际数据库。
检查事项:
- 客户机房是否允许外网访问;
- 客户机房如果有访问白名单,名单是否包含了纷享所有出口ip;
- 客户机房是否开启了代理使用的端口号。
二、配置截图
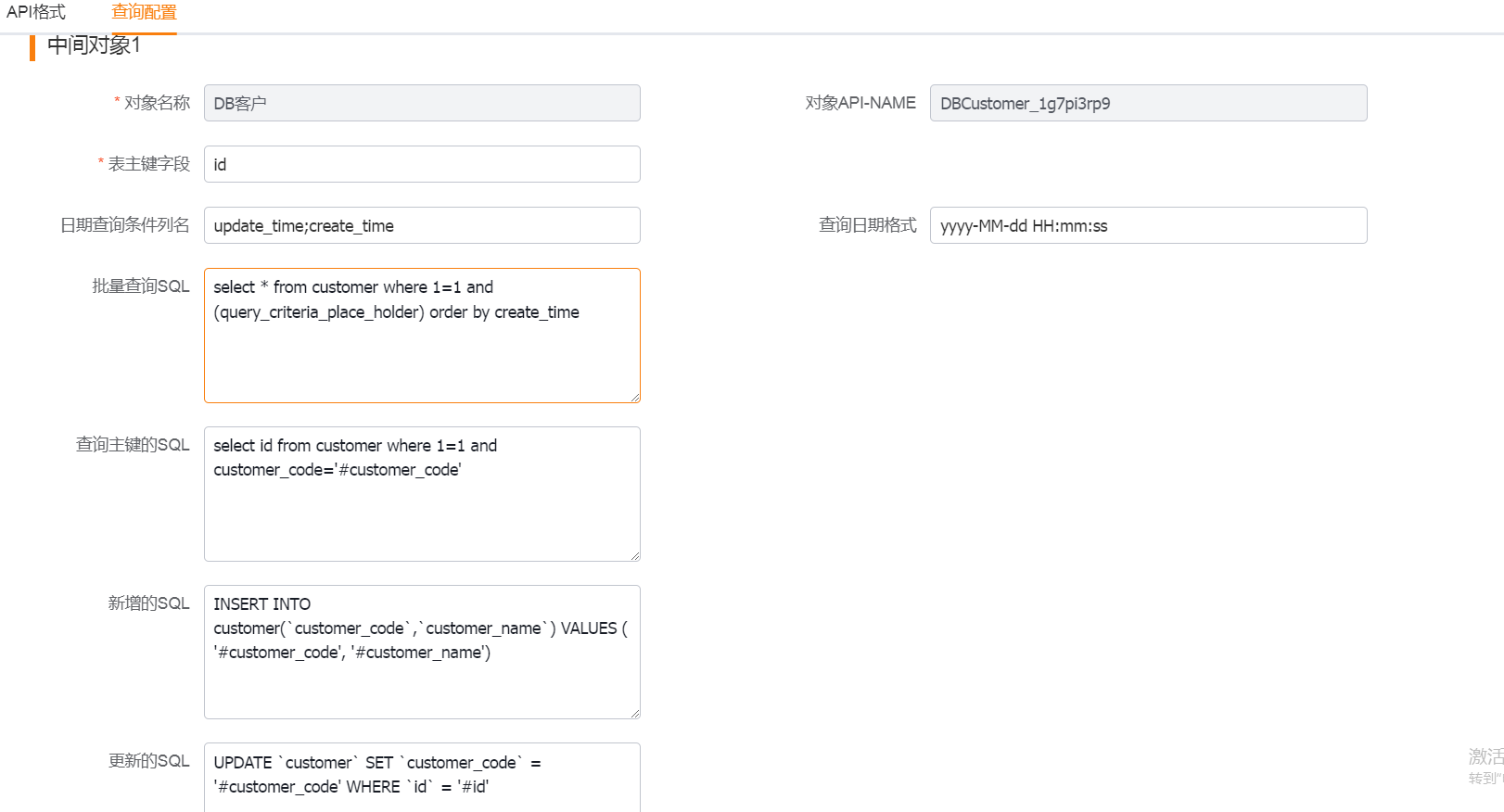
1.主对象
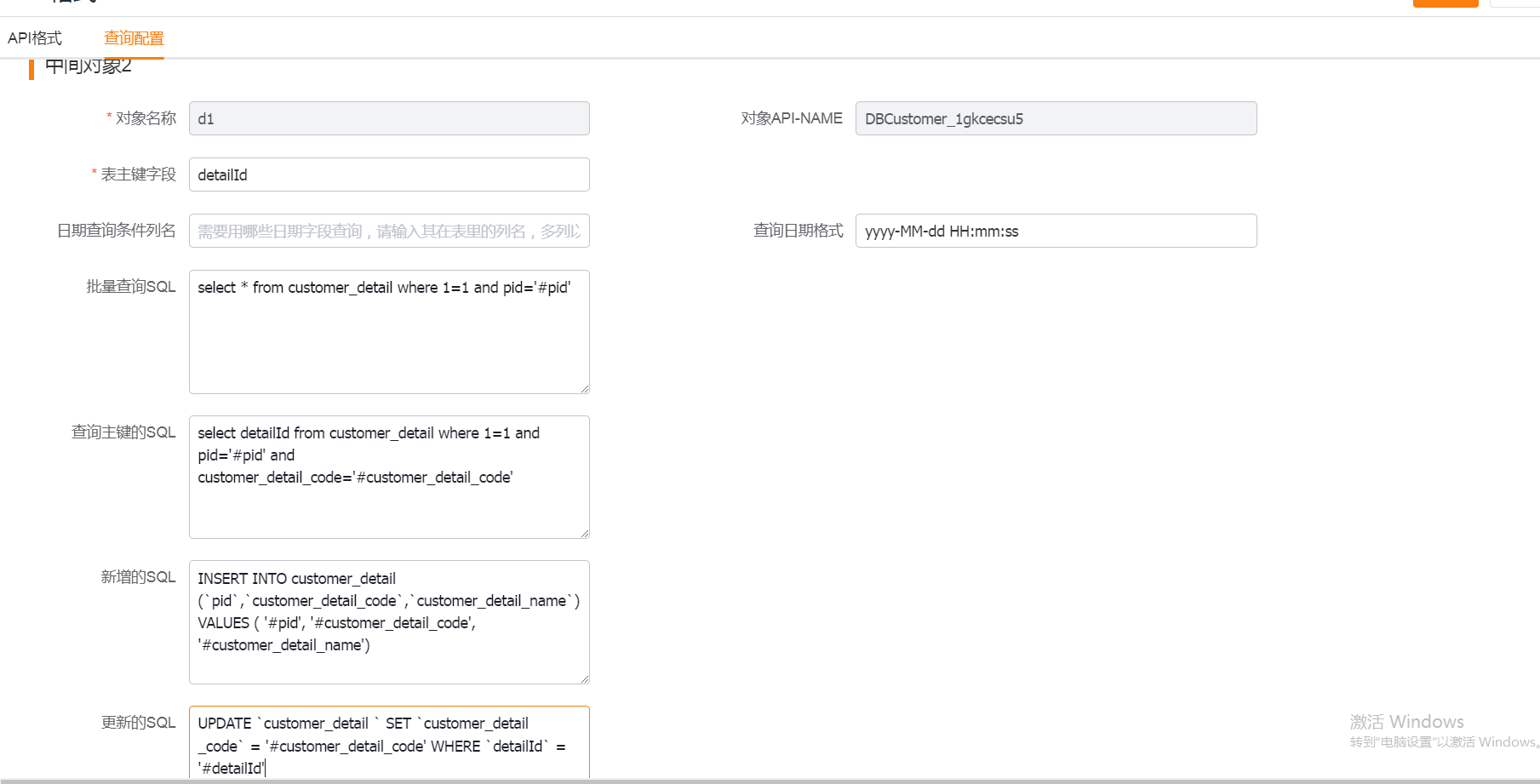
2.从对象
三、配置说明
1.常规配置说明
1) 表主键字段:表的唯一性字段
2) 日期查询条件列名:用于查询的的时间字段,多个字段使用[;]或者[,],如果包含[;]就使用[;]分隔,否则使用[,]分隔
3) 查询日期格式:用于查询的日期字段格式
4) 批量查询sql:用于轮询批量查询的sql,主对象上的sql如果有占位符[query_criteria_place_holder],那么查询条件会替换占位符,如果没有,查询条件会拼接在后面。最好加上order by,可以减少漏数据概率。
5) 查询主键的SQL: 新增后反查主键的sql
6) 新增的sql:用于CRM到中间库插入表的sql模板:模板所有的需要替换的值。都以 '#字段列表中的字段名称' 的格式进行书写 ,如果明细中需要引用主表的主键:以'#pid'替换
7) 更新的sql:用于CRM到中间库更新表的sql模板:模板所有的需要替换的值。都以 '#字段列表中的字段名称' 的格式进行书写 , 如果明细中需要引用主表的主键:以'#pid'替换
2.特殊配置(临时表)说明
1)如果没有【日期查询条件列名】,让客户IT在需要对接的数据库(如果执行不成功,根据具体的数据库类型修改一下语句)执行如下创建临时表的sql。
这个临时表的作用:因为没有日期字段,所以每次读取都会是全量读表的数据。
集成平台每次调用都是带时间的轮询,都是从这个临时表按时间读取数据,同时触发一个异步线程从数据库表读取数据插入临时表(插入时会对比数据md5,发生了变化的才会变更时间,只有变更了时间的,接口才能从临时表增量获取到)。
第一次调用接口,从临时表读取数据,没有数据,直接返回,同时触发了一个异步线程,异步线程在从数据库读取数据插入临时表。
第二次调用接口,临时表有数据了,取到数据返回,最后一页数据再触发一个异步线程,循环往复。
-- PostgreSQL
CREATE TABLE sync_obj_record (
id int8 NOT NULL,
obj_name varchar NOT NULL,
md_str varchar NOT NULL,
data_id varchar NOT NULL,
data_body text NOT NULL,
"version" int NOT NULL,
create_time int8 NOT NULL,
update_time int8 NOT NULL,
CONSTRAINT sync_obj_record_pk PRIMARY KEY (id)
);
CREATE UNIQUE INDEX sync_obj_record_obj_name_idx ON sync_obj_record (obj_name,data_id);
-- ORACLE
CREATE TABLE sync_obj_record (
id NUMBER(19) NOT NULL,
obj_name VARCHAR2(255) NOT NULL,
md_str VARCHAR2(255) NOT NULL,
data_id VARCHAR2(255) NOT NULL,
data_body CLOB NOT NULL,
version NUMBER(19) NOT NULL,
create_time NUMBER(19) NOT NULL,
update_time NUMBER(19) NOT NULL,
CONSTRAINT sync_obj_record_pk PRIMARY KEY (id)
);
CREATE UNIQUE INDEX sync_obj_record_obj_name_idx ON sync_obj_record (obj_name, data_id);-- SQLServerCREATE TABLE [dbo].[sync_obj_record] (
[id] bigint NOT NULL,
[obj_name] varchar(100) COLLATE Chinese_PRC_CI_AS NOT NULL,
[md_str] varchar(32) COLLATE Chinese_PRC_CI_AS NOT NULL,
[data_id] varchar(100) COLLATE Chinese_PRC_CI_AS NOT NULL,
[data_body] text COLLATE Chinese_PRC_CI_AS NOT NULL,
[version] int NOT NULL,
[create_time] bigint NOT NULL,
[update_time] bigint NOT NULL,
CONSTRAINT [PK__sync_obj__3213E83F46CC8028] PRIMARY KEY CLUSTERED ([id])
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
)
ON [PRIMARY]
TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[sync_obj_record] SET (LOCK_ESCALATION = TABLE)
GO
CREATE UNIQUE NONCLUSTERED INDEX [sync_obj_record_u1]
ON [dbo].[sync_obj_record] (
[obj_name] ASC,
[data_id] ASC
)-- MySQL
CREATE TABLE sync_obj_record (
id INT NOT NULL,
obj_name VARCHAR(255) NOT NULL,
md_str VARCHAR(255) NOT NULL,
data_id VARCHAR(255) NOT NULL,
data_body TEXT NOT NULL,
version INT NOT NULL,
create_time BIGINT NOT NULL,
update_time BIGINT NOT NULL,
PRIMARY KEY (id)
);
CREATE UNIQUE INDEX sync_obj_record_obj_name_idx ON sync_obj_record (obj_name, data_id);四、配置作用说明
结合配置说明的序号1、2、3、4、5、6、7、8,以及配置页面图片的sql
1.单条查询
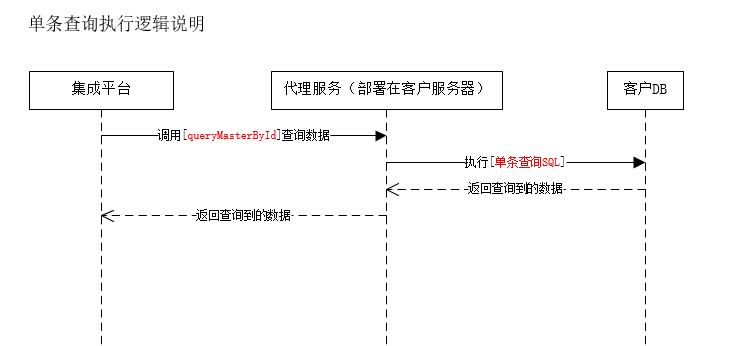
(1)主对象
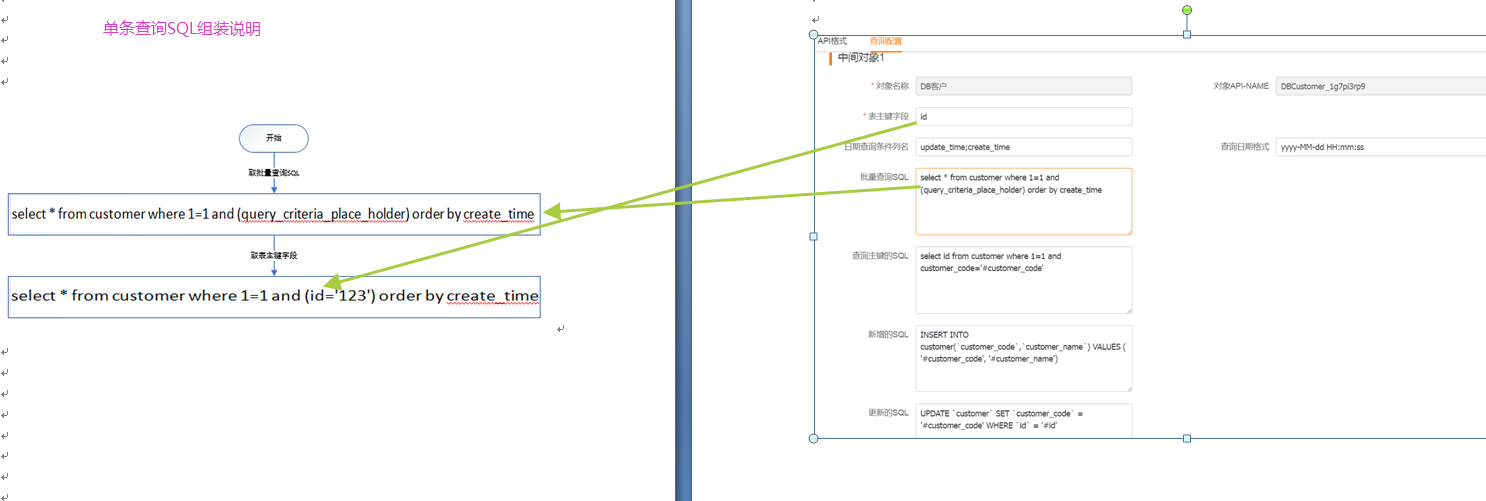
查询主数据id(主数据主键字段的值)为:“123”
使用到的配置:1(表主键字段)和4(批量查询sql)
自动拼接出查询条件:[表主键字段='123'],
如果批量查询语句有占位符,那么条件会替换占位符,最终生成单条查询语句:[select * from customer where 1=1 and (id='123') order by create_time],
如果没有占位符,条件会自动拼接在查询语句后面:批量查询sql+and+条件,生成单条查询语句。
(2)从对象
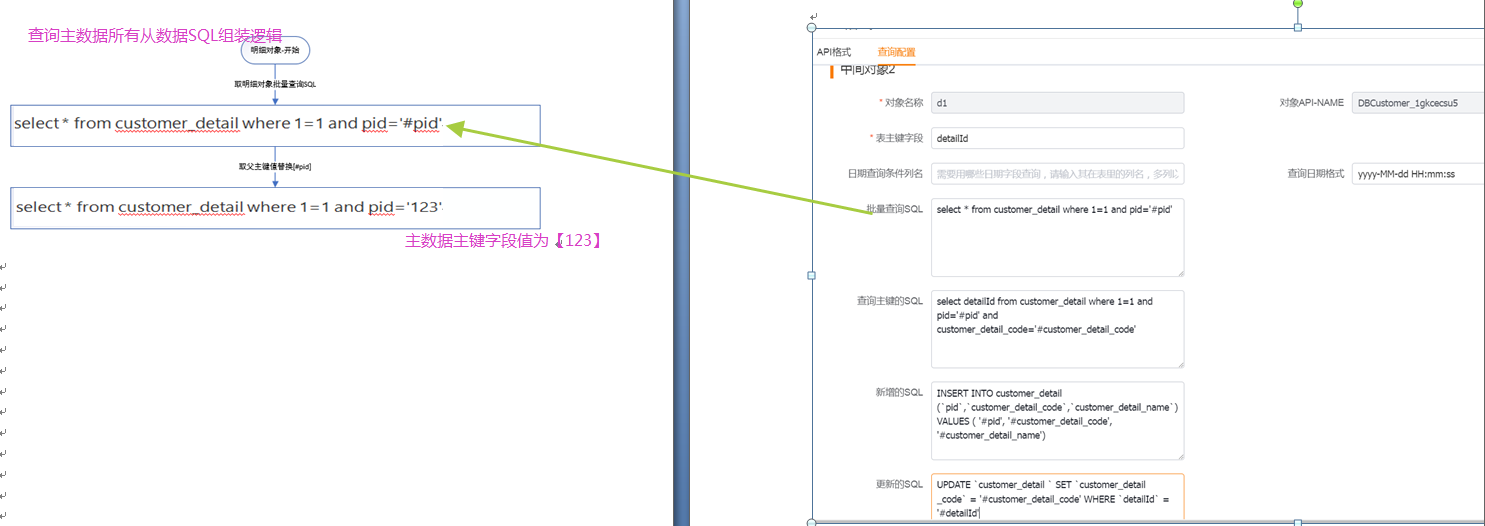
如果有从对象,会从查到的主数据,从主数据中取主数据的1(表主键字段)的值(主数据id),
然后把明细对象的4(批量查询语句)中的['#pid']替换为['123'] ,生成查询该主数据对应明细数据的查询语句:[select * from customer_detail where 1=1 and pid='123']
2.批量查询
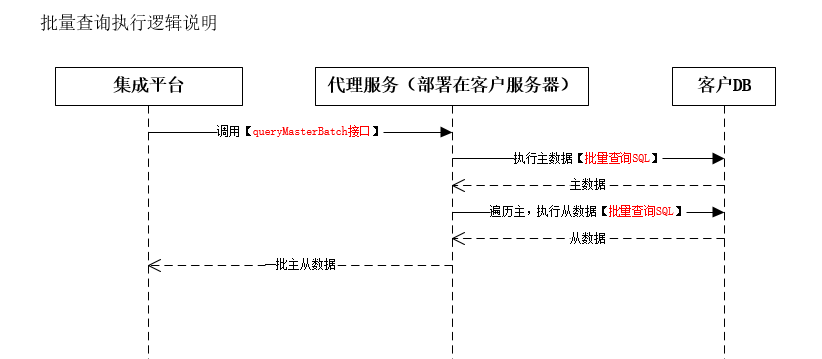
(1)主对象
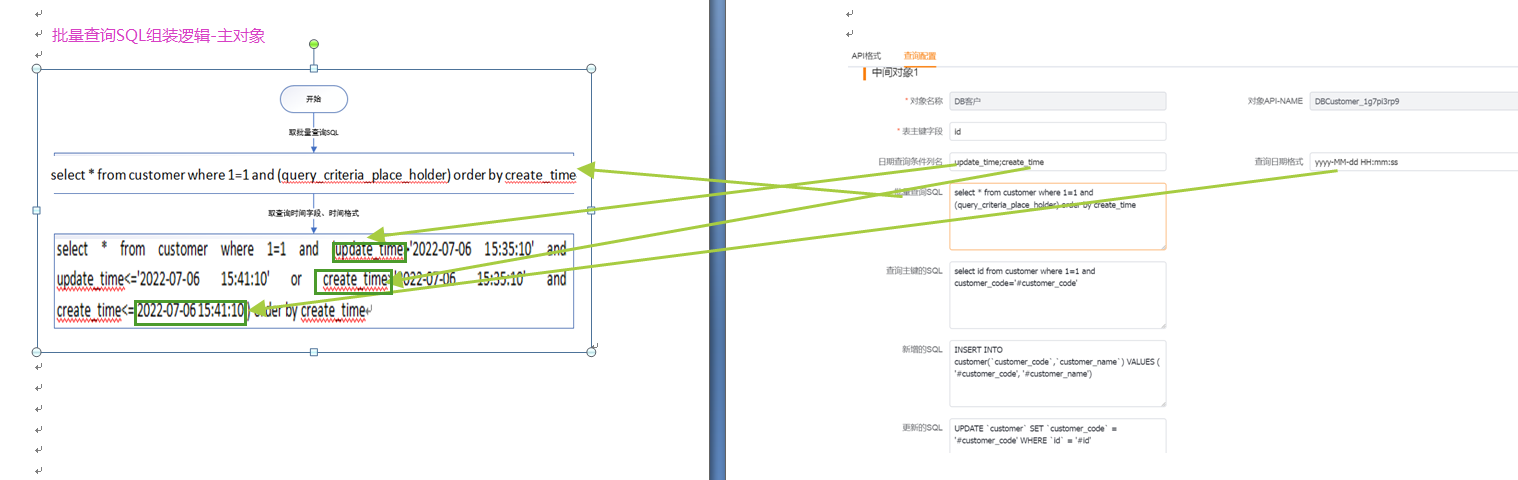
查询开始时间是:1657092910000,结束时间是:1657093270000
使用到的配置:2(查询时间字段)、3(查询日期格式)和4(批量查询sql)
使用3(查询日期格式)把时间戳转换成对于时间格式:【开始时间是:2022-07-06 15:35:10,结束时间是:2022-07-06 15:41:10】
使用2(查询时间字段),如果包含[;],通过[;]分隔出多个时间字段,如果不包含[;],使用[,]分隔出时间字段,拼接字段与时间,拼接得到查询条件为[update_time>'2022-07-06 15:35:10' and update_time<='2022-07-06 15:41:10' or create_time>'2022-07-06 15:35:10' and create_time<='2022-07-06 15:41:10']
使用主数据查询语句4(批量查询语句),如果批量查询语句有占位符,那么条件会替换占位符,最终生成批量查询语句:[select * from customer where 1=1 and (update_time>'2022-07-06 15:35:10' and update_time<='2022-07-06 15:41:10' or create_time>'2022-07-06 15:35:10' and create_time<='2022-07-06 15:41:10') order by create_time],如果没有占位符,条件会自动拼接在查询语句后面:批量查询语句+and+条件,生成批量查询语句。
(2)从对象-逻辑见单条查询
从对象,先遍历查到的主数据,从主数据中取主数据的1(主键字段)的值(主数据id),比如是:“123”,然后把明细对象的4(批量查询语句)中的[#pid]替换为主数据id,生成查询该主数据对应明细数据的查询语句:[select * from customer_detail where 1=1 and pid='123']
3.创建数据
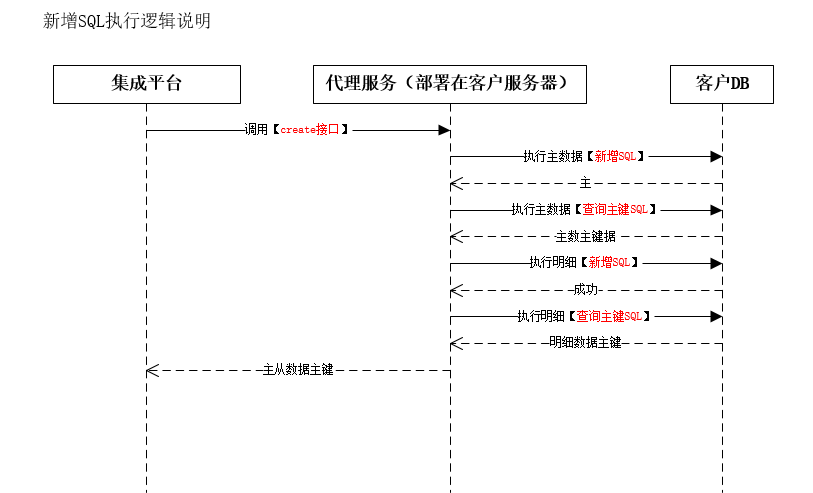
(1)主对象-新建语句
数据体是【{"masterFieldVal":{"customer_code":"code1"},"detailFieldVals":{"d1obj":[{"customer_detail_code":"detailCode1"}]}}】,
使用到的配置:主从的5(查询主键的SQL)和6(新增的sql)
使用到6(新增的sql),主数据上6(新增的sql)中的['#customer_code']被数据体中的主数据[customer_code]的值['code1']替换掉,6(新增的sql)中的['#customer_name']由于主数据[customer_name]的值为null所以被替换为[null],最终得到插入sql[INSERT INTO customer(`customer_code`,`customer_name`) VALUES ( 'code1', null)]
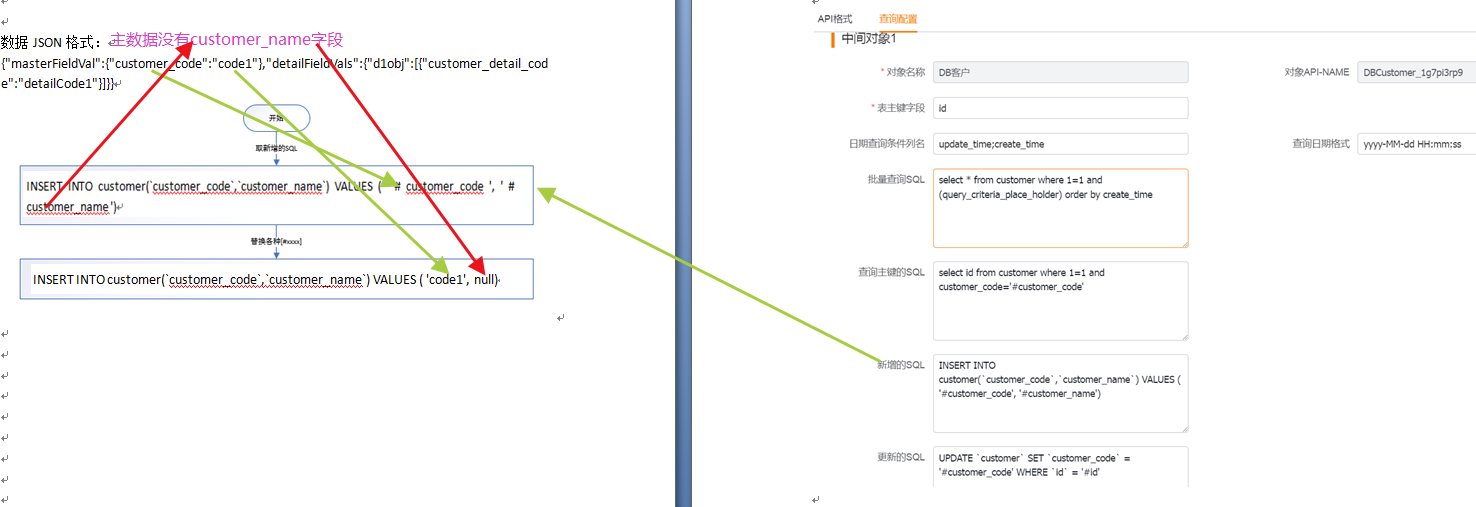
(2)主对象-查询主键语句
使用到5(查询主键的SQL),主数据上5(查询主键的SQL)中的['#customer_code']被数据体中的主数据[customer_code]的值['code1']替换掉,最终得到查询主键sql[select id from customer where 1=1 and customer_code='code1']
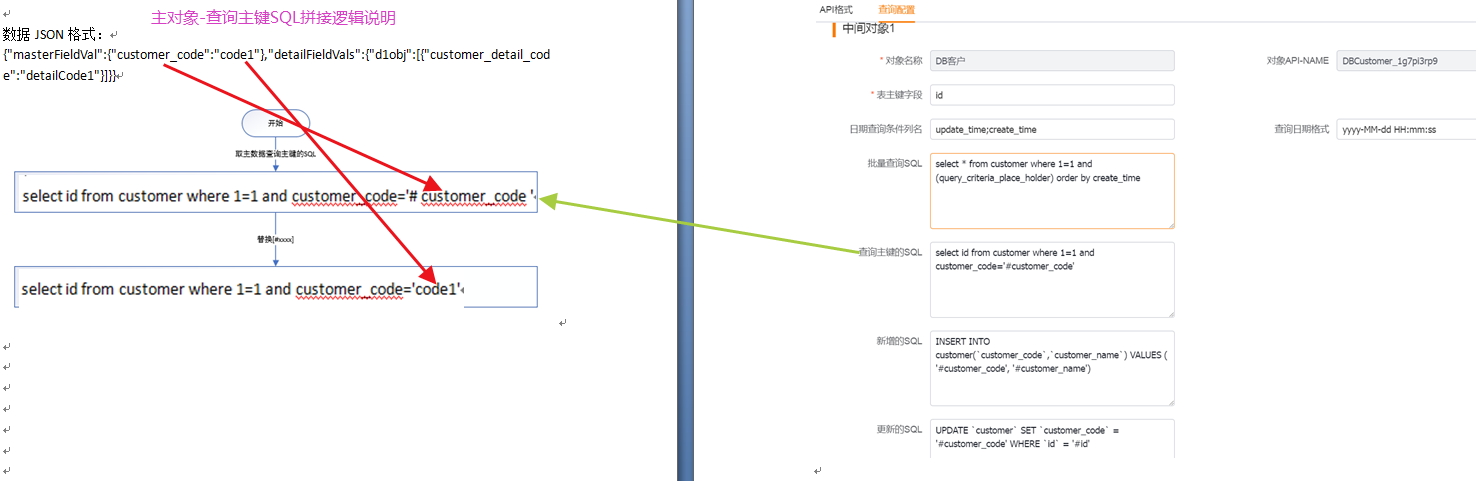
(3)从对象-新建语句
使用到6(新增的sql),从数据上6(新增的sql)中的['#customer_detail_code']被数据体中的从数据[customer_detail_code]的值['detailCode1']替换掉,从数据上6(新增的sql)中的['#customer_detail_name']由于主数据[customer_detail_name]的值为null所以被替换为[null],最终得到初步的插入sql[INSERT INTO customer_detail (`pid`,`customer_detail_code`,`customer_detail_name`) VALUES ( '#pid', 'detailCode1', null)]
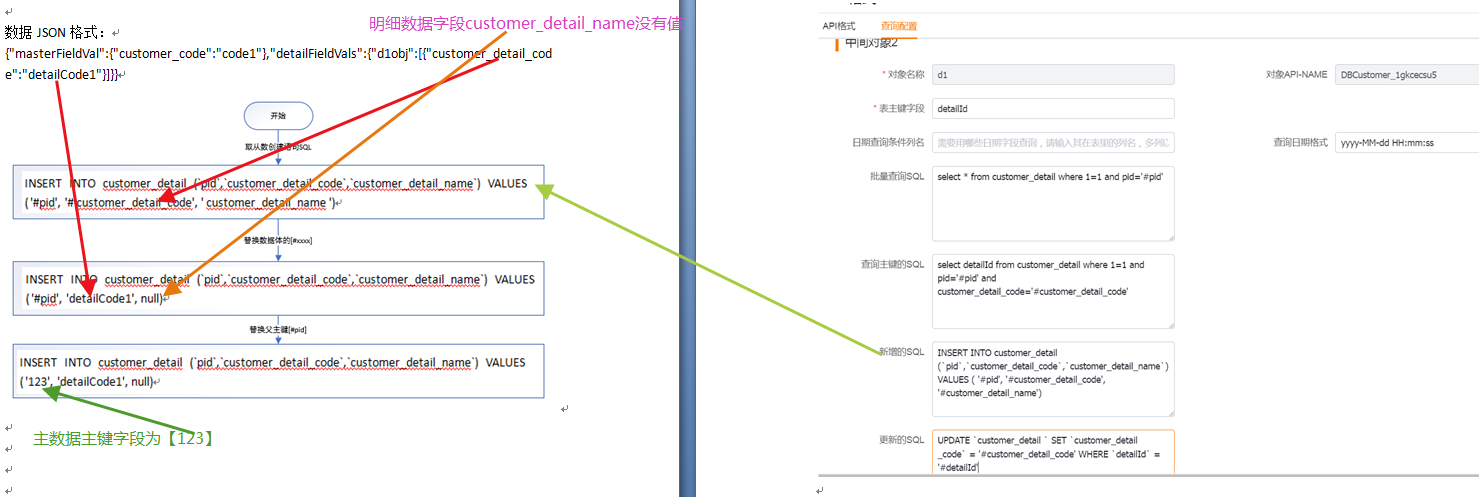
(4)从对象-查询主键语句
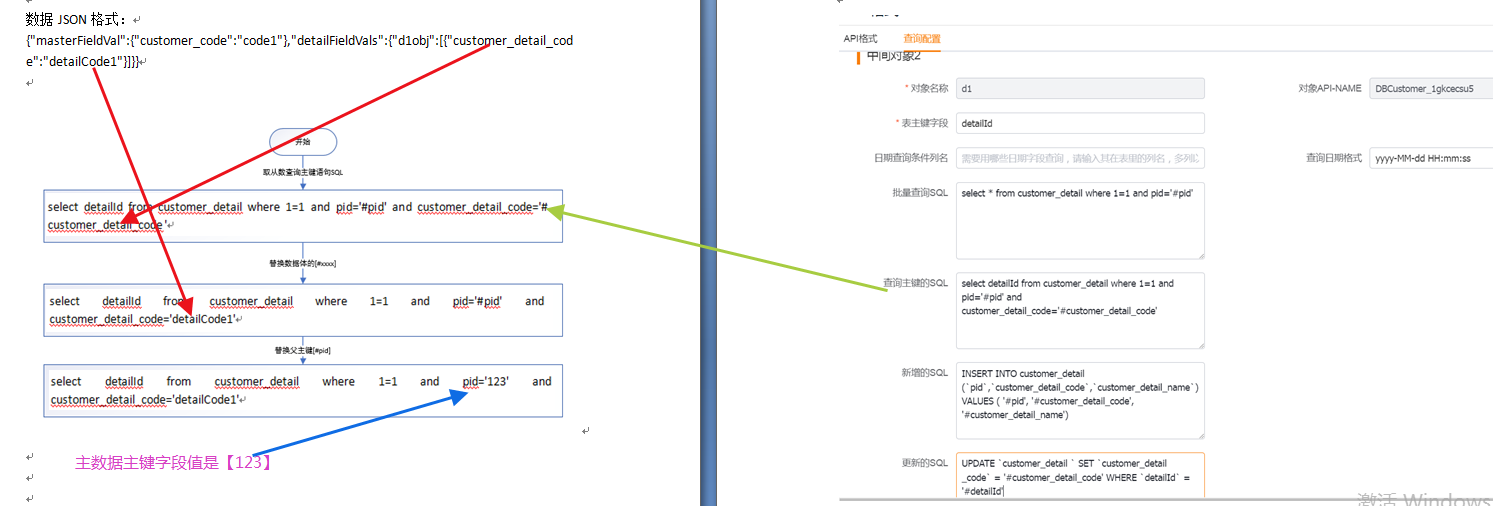
使用到5(查询主键的SQL),从数据上5(查询主键的SQL)中的['#customer_detail_code']被数据体中的从数据[customer_detail_code]的值['code1']替换掉,最终得到初步的查询主键sql[select detailId from customer_detail where 1=1 and pid='#pid' and customer_detail_code='detailCode1']
(5)主从sql执行步骤(非事务性)
执行主数据插入sql,执行成功后,执行主数据查询主键sql,得到主数据id,比如是“1234”,然后从数据的新增sql和查询主键的sql中['#pid']会被替换为['1234'],形成最终的从数据新增sql[INSERT INTO customer_detail (`pid`,`customer_detail_code`,`customer_detail_name`) VALUES ( '1234', 'detailCode1', null)],从数据查询主键sql[select detailId from customer_detail where 1=1 and pid='1234' and customer_detail_code='detailCode1'],先执行从数据插入sql,再执行从数据查询主键sql。
4.更新数据
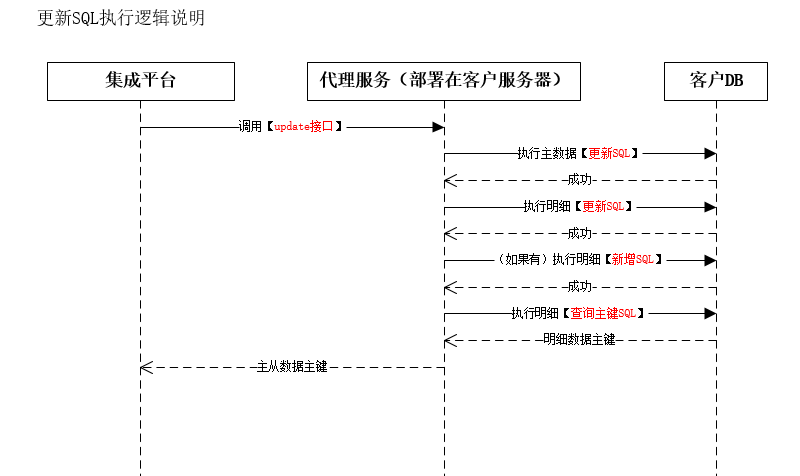
(1)主对象-更新语句
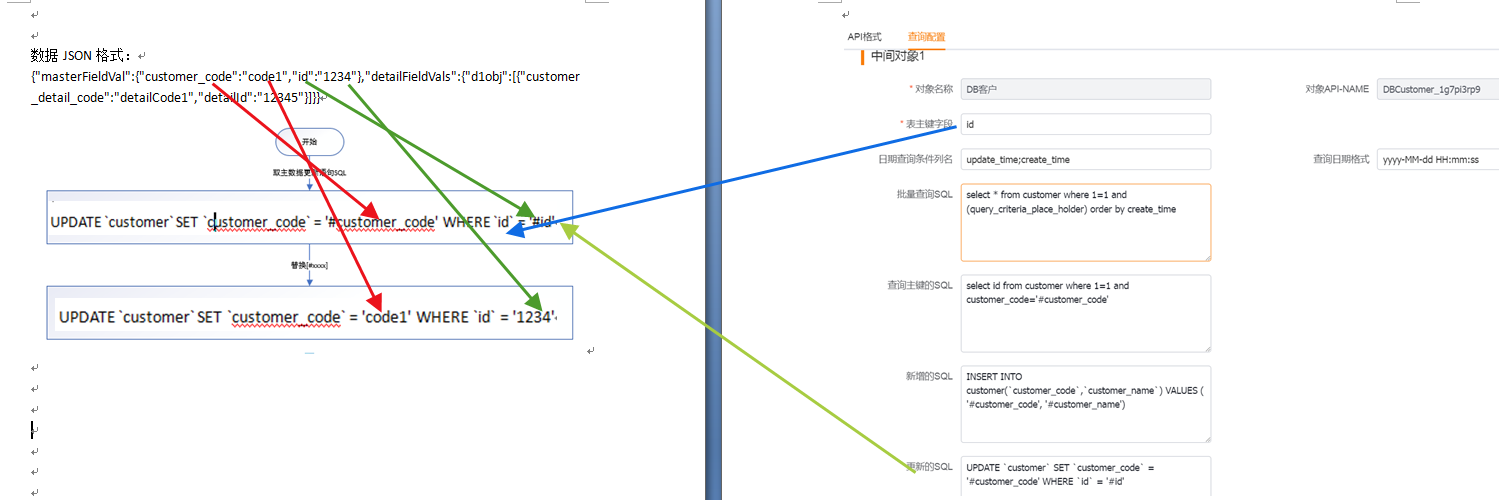
数据体是【{"masterFieldVal":{"customer_code":"code1","id":"1234"},"detailFieldVals":{"d1obj":[{"customer_detail_code":"detailCode1","detailId":"12345"}]}}】,
使用到的配置:主从的7(更新的sql),如果明细有新增,会使用到明细的5(查询主键的SQL)和6(新增的sql)
使用到7(更新的sql),主数据上7(更新的sql)中的['#customer_code']被数据体中的主数据[customer_code]的值['code1']替换掉,7(更新的sql)中的['#id']被数据体中的主数据[id]的值['1234']替换掉,最终得到更新sql[UPDATE `customer` SET `customer_code` = 'code1' WHERE `id` = '1234']
(2)从对象-更新语句
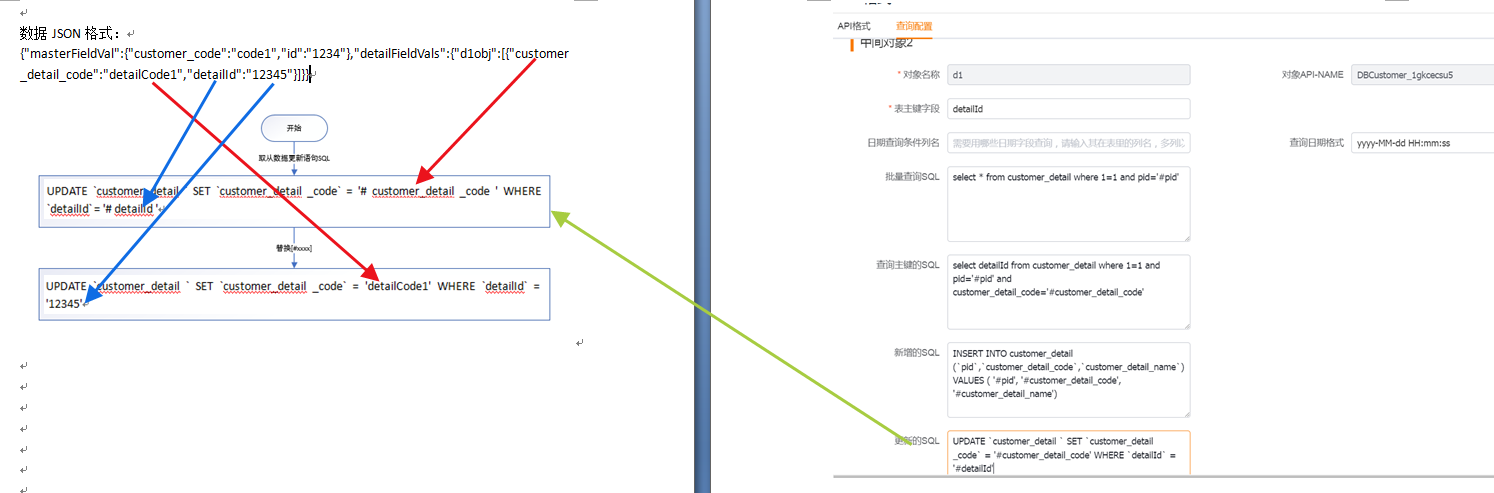
使用到7(更新的sql),从数据上7(更新的sql)中的['#customer_detail_code']被数据体中的从数据[customer_detail_code]的值['detailCode1']替换掉,7(更新的sql)中的['#detailId']被数据体中的从数据[detailId]的值['12345']替换掉,最终得到初步的插入sql[UPDATE `customer_detail ` SET `customer_detail _code` = 'detailCode1' WHERE `detailId` = '12345']
如果明细有新增,步骤如上明细新增数据的步骤。暂不支持明细的作废删除
五、新版本功能说明
新开通的连接器,已经强制需要使用1.1以上版本代理服务进行连接。
1. 代理服务1.1版本
(1)新特性
- 支持配置多数据,集成支持数据库:MySQL,PostgreSQL,Oracle,SQLServer
- 支持外挂jdbc驱动包,从而实现对默认数据库之外的数据库访问,已测试达梦DM8
- 新的配置文件格式,更简洁方便
- 新增服务信息等接口,方便集成平台获取代理服务信息
- 支持查询多sql执行(为了支持无offset轮询时,一次查询需要使用两个SQL查询的情况)
- 优化错误返回,更全面的异常捕捉
- 升级依赖jar,包括spring-boot,fastjson等,防止漏洞
- 开启druid的统计功能
- 对集成平台全环境兼容(集成平台分环境发布,会多版本共存,旧版本环境也可正常访问新版本代理服务)
(2)部署说明
附件为代理程序1.0和1.1的jar包
配置文件:
服务有两种配置。 第一种是spring的配置。 默认启用spring的prod环境,所以可以在jar包同级目录创建application-prod.yml增加配置。 示例:
# application-prod.yml
setting:
# 设置文件目录 可以使用相对路径,不配置时,默认使用工作目录下的setting文件夹
dir: D:\project\DBMidProxyServer\setting
server:
servlet:
context-path: /dev
另外一种是使用hutool的配置。其中user.setting代码已经支持了动态加载。 db.setting未支持。 以上setting.dir指定的目录下必须包含两个配置文件db.setting和user.setting
# user.setting
# 安全性配置
username=admin
password=1234qwer
#db.setting 数据库配置,
#使用druid的配置参考https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%88%97%E8%A1%A8
#分组名就是作为数据源名称
[db1]
url=jdbc:postgresql://localhost:5432/db1?ssl=false
username=postgres
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db2]
url=jdbc:postgresql://localhost:5432/db2?ssl=false
username=postgres
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db3]
# mysql
url=jdbc:mysql://localhost:3306/db3?useSSL=false&characterEncoding=UTF-8&connectionTimeZone=Asia/Shanghai
username=root
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db4]
# sqlserver
url=jdbc:sqlserver://;serverName=localhost;databaseName=db4;encrypt=true;trustServerCertificate=true
username=sa
password=8kn0ye66JxO5
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[db5]
# oracle
url=jdbc:oracle:thin:@127.0.0.1:1521:XE
username=dbproxy
password=1234qwer
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
[dm8]
# 达梦数据库 需要另外增加驱动启动
url=jdbc:dm://localhost:5236?LobMode=1
username=SYSDBA
password=SYSDBA001
queryTimeout=30
initialSize=5
maxActive=20
testWhileIdle=true
# 未集成驱动的,需要指定jdbc驱动的jar包。
driverJarPath=D:\driver\db-driver\DmJdbcDriver18.jar
运行命令:
java -jar DBMidProxyServer.jar
2. 集成平台配置
注:以下功能依赖上方新版代理服务,旧配置不影响正常运行,需要新功能,重新部署1.1版本以上代理服务即可。
(1)连接信息
新版本代理服务部署后,支持通过api获取代理服务版本、数据源信息、数据库类型等。
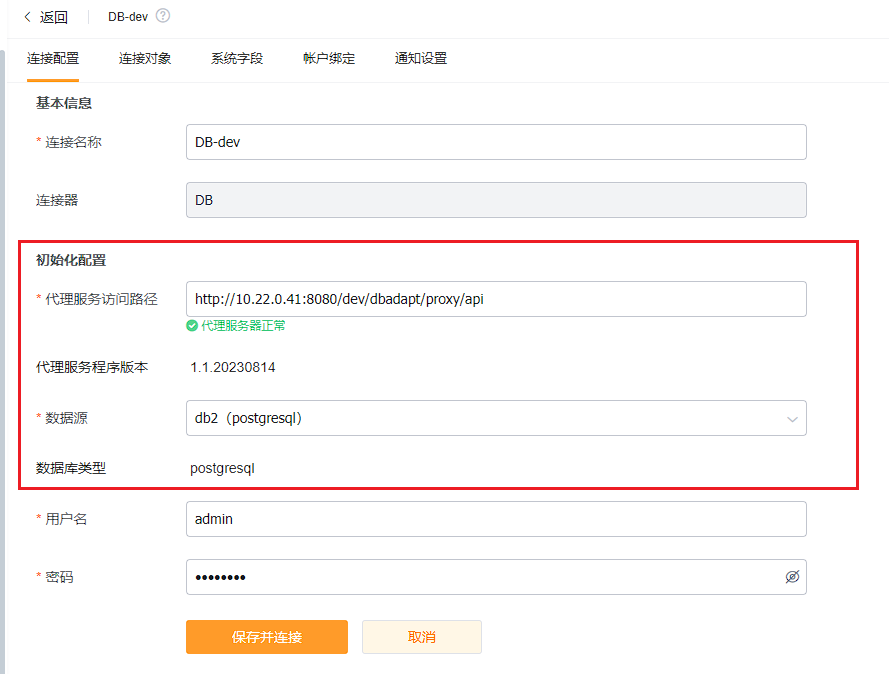
(2)查询SQL
增加一种不使用offset的查询方式。原理:深入研究分页查询漏数据问题并寻求优化策略 (lexiangla.com)
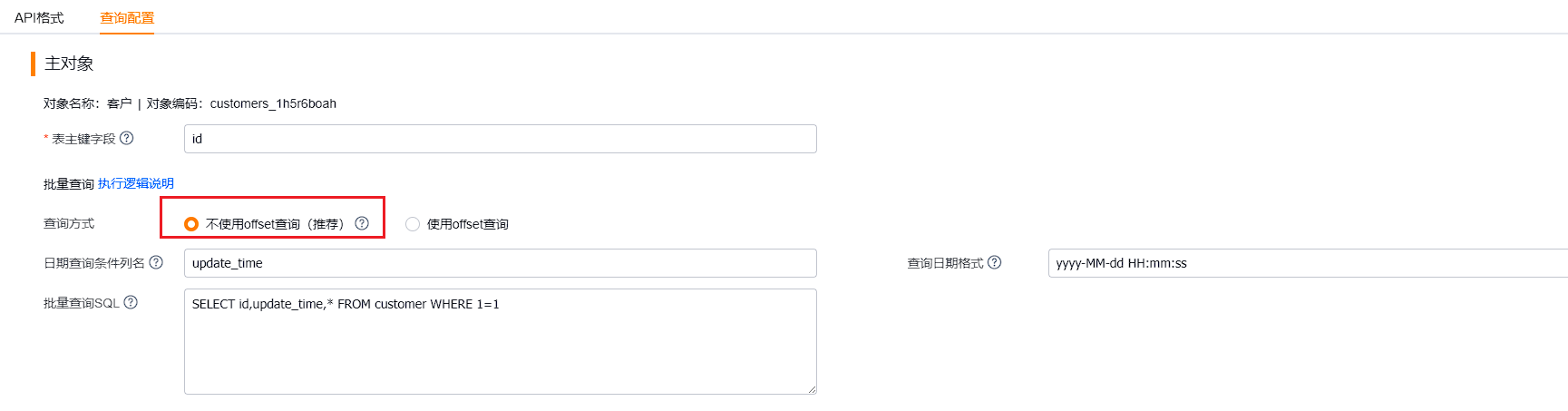
配置条件和注意事项:
- 使用唯一的日期查询列
- 查询sql需要查询主键字段和日期字段
- 需要有相应索引,否则表数据较大时,查询效率慢。(所以需要测试sql需要能走到索引上)
优势:
- 只要不出现将新数据更新为旧的更新时间,必定不会漏数据。
- 配置索引后,无深翻页,查询效率高。(但配置不一定简单)
示例SQL 和执行逻辑:
示例配置:
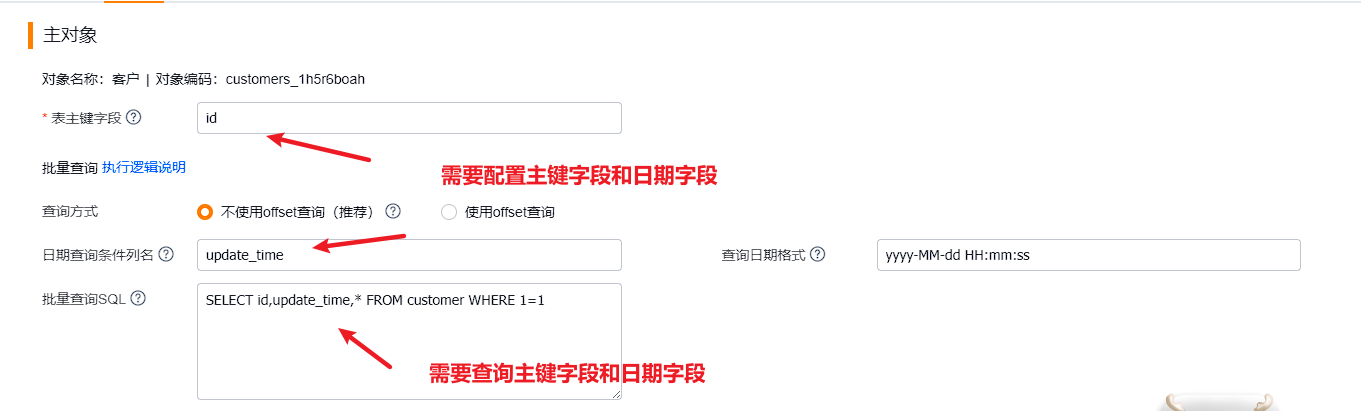
实际查询语句示例(PostgreSQL):
-- 需要查询T1到T2之间的数据
-- 第一次查询SQL
select * from customer where update_time>T1 and update_time<=T2 ordey by update_time,id limit 100
-- 第n次查询SQL,其中{lastMaxUpdateTime}每次替换为上次查询的最后一条数据的updateTime,{lastMaxId}每次替换为上次查询的最后一条数据的id
select * from customer where update_time={lastMaxUpdateTime} and id > {lastMaxId} ordey by update_time,id limit 100
select * from customer where update_time> {lastMaxUpdateTime} and update_time<=T2 ordey by update_time,id limit 100
所以,应该在数据库创建索引如下(需要自行操作):
-- 对数据库创建的索引
CREATE INDEX idx_id_update_time ON customer (update_time,id);
目前已适配语法:PostgreSQL,Mysql,Oracle,SqlServer