
一、算粒说明
纷享接入了市面上主流的大模型,由于各厂商提供的模型刊例价不同,纷享销客使用算粒作为AI平台的统一计费单位,1算粒 = 0.10元人民币。
二、计费规则
在使用过程中(对话、工作流、开发、调试等),会根据实际资源消耗(即背后的 token 资源)自动扣除一定额度。额度消耗取决于以下几项:

三、算粒消耗估算方法
1. Agent执行估算
Agent执行一次(一问一答)的总算粒=意图识别消耗算粒+所有提示词模板消耗算粒+所有AI操作消耗的算粒+最终内容整合输出消耗的算粒
- 模型相关的估算
原则上要估算输入和输出的token,意图识别和最终内容整合必须进行估算,提示词模板按照agent编排配置的实际情况进行估算。
各阶段算粒数=输入字符数*字符token转换比例(中文按1.2,英文按1.3)
- 意图识别:输入内容一般为用户在Agent输入框下达的指令,字符数一般不会超200字;输出为Agent所要执行的技能及操作,字符数也不会太大,可按1000token进行估算。
- 最终内容整合:输入内容一般为Agent执行中所有执行的操作输出的总和,可直接估算其字符数,输出一般为用户指令的内容
- 提示词模板:输入内容为提示词模板中配置的场景变量预期承接的内容,可根据变量含义估算字符数,输出为模板中定义的输出内容
- AI操作估算:
先拆解一次用户指令会执行多少AI操作,然后基于复杂度参考消耗区间进行估算,AI操作消耗如下
| AI操作 | 消耗估算(算粒/次) |
| 互联网搜索 | 0.5-1 |
| 创建对象数据类操作(创建客户、日程等) | 0.12-0.5 |
| 查询对象数据类操作 | 0.3-1 |
| 知识库检索类操作 | 0.2-0.4 |
| 文本解析成文字 | 根据文件类型与文档分辨率动态使用解析模型,各模型计费如下: facishare-text-parse-economy:0.1算粒/页;facishare-doc-convert-economy 0.1 算粒/页; facishare-doc-parse-economy 0.2 算粒/页; facishare-vl-parse-economy 按Token计费,与文档分辨率正相关,0.01算粒/1k 输入,0.04算粒/1k 输出; facishare-doc-parse-s-balance 0.2 算粒/页; facishare-doc-parse-gigantic 0.6 算粒/页; facishare-asr-balance 0.004算粒/页; facishare-asr-s-balance 0.01算粒/页; facishare-doc-parse-balance 0.4算粒/页baidu-diff-latest 2算粒 |
2. Flow估算
基于Flow设计,识别Flow中使用的AI操作以及提示词模板,并估算个节点的算粒消耗
其中,Flow中提示词模板及AI操作的计费参考上表,与在agent中使用时的计费逻辑一致
3. RAG知识切片向量化入库
在使用知识库做智能问答或检索知识生成内容时,需要考虑知识切片向量化入库的成本,以及基于用户问题召回相关知识切片的成本。该过程的详细费用参考该文档进行估算https://365.kdocs.cn/l/caZSJg7Xkkrt
切片向量化入库:
文档:pdf文件0.1算粒/页
图片:0.1算粒/张
四、场景案例
以下额度消耗为正常使用的均值,仅作参考,实际使用中额度消耗量可能根据用户要求和任务复杂度而波动
| 场景 | 估算案例 | 使用模型 | 预估算粒消耗 |
| 日常客服对话 | 一问一答,智能客服检索知识库内容后回答问题 | deepseek-v3.2 | 0.3算粒 |
| 长文字摘要 | 输入5万字,输出2000字 | deepseek-v3 | 1.4算粒 |
| 客户情报收集/洞察 | 搜集工商信息、CRM信息、联网搜索信息对客户/企业做全方位洞察 | deepseek-v3.2 | 1.2算粒 |
| 周日报摘要 | 总结一周10条销售记录 | deepseek-v3.2 | 0.1算粒 |
| 内容质检 | 对销售填写的销售记录/外勤/商机跟进的内容质量进行质检,每次约输入300字 | deepseek-v3 | 0.06算粒 |
| 知识库问答 | deepseek-v3 | 0.4算粒/次 | |
| 文件解析 | 将文件转成文字并按要求摘要,普通精度要求,文件共10页,2万字,输出200字关键信息 | deepseek-v3.2 | 10*0.02+2*1.2*0.2+1.2*0.3*0.02=0.8算粒/次 |
五、模型费用
1. 百度文心一言
| 模型名称 | 胜任场景 | 上下文长度 | 输入单价(元/百万token) | 输出单价(元/百万token) | 输入算粒消耗(算粒/百万token) | 输出算粒(算粒/百万token) |
| ERNIE 3.5系列 | 内容生成 | 8K | 0.80 | 2.00 | 8.00 | 20.00 |
| ERNIE 4.0系列 | 推理&联网搜索 | 8K | 4.00 | 16.00 | 40.00 | 160.00 |
| ERNIE 4.5系列 | 推理&联网搜索 | 8K | 4.00 | 16.00 | 40.00 | 160.00 |
2. 阿里云
| 模型名称 | 胜任场景 | 上下文长度 | 输入单价(元/百万token) | 输出单价(元/百万token) | 输入单价(算粒/百万token) | 输出单价(算粒/百万token) |
| qwen-turbo | 联网搜索 | 输入128K/输出8K | 0.30 | 0.60 | 3.00 | 6.00 |
| qwen-plus | 推理&联网搜索 | 输入128K/输出8K | 0.80 | 2.00 | 8.00 | 20.00 |
| qwen-max | 推理&联网搜索 | 输入32K/输出8K | 2.40 | 9.60 | 24.00 | 96.00 |
| qwen3-235b | 内容生成 | 输入128K/输出16K | 2.00 | 8.00 | 20.00 | 80.00 |
| qwen3-30b | 内容生成 | 输入126K/输出32K | 0.75 | 3.00 | 7.50 | 30.00 |
| qwen3.5-plus | 内容生成 | 输入991K/输出64K | 0.80 | 4.80 | 8.00 | 48.00 |
| qwen3.5-397b-a17b | 内容生成 | 输入254K/输出64K | 1.20 | 7.20 | 12.00 | 72.00 |
| qwen-vl-plus | 视觉理解 | 输入6K/输出2K | 1.50 | 4.50 | 15.00 | 45.00 |
| qwen-vl-max | 视觉理解 | 输入30K/输出2K | 3.00 | 9.00 | 30.00 | 90.00 |
| qwen2.5-vl-32b | 视觉理解 | 输入126K/输出8K | 8.00 | 24.00 | 80.00 | 240.00 |
| qwen3-vl-plus | 视觉理解 | 输入252K/输出32K | 1.00 | 10.00 | 10.00 | 100.00 |
| deepseek-v3 | 内容生成 | 输入57K/输出8K | 2.00 | 8.00 | 20.00 | 80.00 |
| deepseek-v3.1 | 内容生成 | 输入96K/输出64K | 4.00 | 12.00 | 40.00 | 120.00 |
| deepseek-v3.2 | 内容生成 | 输入96K/输出64K | 2.00 | 3.00 | 20.00 | 30.00 |
| deepseek-r1 | 推理 | 输入57K/输出8K | 4.00 | 16.00 | 40.00 | 160.00 |
3. 腾讯混元
| 模型名称 | 胜任场景 | 上下文长度 | 输入单价(元/百万token) | 输出单价(元/百万token) | 输入单价(算粒/百万token) | 输出单价(算粒/百万token) |
| qwen-image | 图片生成 | - | - | 25.00 | - | 250.00 |
| qwen-image-plus | 图片生成 | - | - | 20.00 | - | 200.00 |
| qwen-image-edit | 图片生成 | - | - | 30.00 | - | 300.00 |
| Hunyuan-Standard | 内容生成&联网搜索 | 输入30K/输出2K | 0.80 | 2.00 | 8.00 | 20.00 |
| hunyuan-pro | 内容生成 | 输入28K/输出4K | 30.00 | 100.00 | 300.00 | 1000.00 |
| hunyuan-large | 内容生成 | 输入28K/输出4K | 4.00 | 12.00 | 40.00 | 120.00 |
| hunyuan-turbo | 内容生成&联网搜索 | 输入28K/输出4K | 2.40 | 9.60 | 24.00 | 96.00 |
| deepseek-v3 | 内容生成 | 64K | 2.00 | 8.00 | 20.00 | 80.00 |
| deepseek-r1 | 推理 | 64K | 4.00 | 16.00 | 40.00 | 160.00 |
4. 字节跳动豆包
| 模型名称 | 胜任场景 | 上下文长度 | 输入单价(元/百万token) | 输出单价(元/百万token) | 输入单价(算粒/百万token) | 输出单价(算粒/百万token) |
| Doubao-Pro-4k | 内容生成 | 4K | 0.80 | 2.00 | 8.00 | 20.00 |
| Doubao-Pro-32k | 内容生成 | 32K | 0.80 | 2.00 | 8.00 | 20.00 |
| deepseek-v3 | 内容生成 | 输入57K/输出8K | 2.00 | 8.00 | 20.00 | 80.00 |
| deepseek-v3.1 | 内容生成 | 输入96K/输出32K | 4.00 | 12.00 | 40.00 | 120.00 |
| deepseek-v3.2 | 内容生成 | 输入96K/输出32K | 2.00 | 3.00 | 20.00 | 30.00 |
| Doubao-seed-2.0-pro | 内容生成 | 256K | 3.20 | 16.00 | 32.00 | 160.00 |
| Doubao-seed-2.0-lite | 内容生成 | 256K | 0.60 | 3.60 | 6.00 | 36.00 |
| Doubao-seed-2.0-mini | 内容生成 | 256K | 0.20 | 2.00 | 2.00 | 20.00 |
5. 智谱
| 模型名称 | 胜任场景 | 上下文长度 | 输入单价(元/百万token) | 输出单价(元/百万token) | 输入单价(算粒/百万token) | 输出单价(算粒/百万token) |
| GLM-4-Flash | 内容生成 | - | 0.10 | 0.10 | 1.00 | 1.00 |
| GLM-4-Air | 内容生成 | - | 0.50 | 0.50 | 5.00 | 5.00 |
| GLM-4V-Plus | 视觉理解 | 8K | 4.00 | 4.00 | 40.00 | 40.00 |
六、常见问题 FAQ
1. 输入和输出价格为什么不同?
输出 token 需要模型进行生成,计算量远大于输入 token 的理解处理,因此输出价格通常高于输入价格(约 2-4 倍)。
2. 多轮对话如何计费?
多轮对话中,历史记录(History)会作为输入参与计费。建议控制上下文长度以降低成本:
3. 如何估算 token 消耗?
| 文本类型 | 估算方法 |
| 中文 | 字数 × 1.2 ≈ token 数 |
| 英文 | 单词数 × 1.3 ≈ token 数 |
4. 算粒和人民币如何换算?
1 算粒 = 0.10 元。例如:消耗 100 算粒 = 10 元
七、用量管理
1.如何查看每轮对话消耗的额度?
系统管理员按以下路径进行查看:管理后台-AI平台管理-调用统计
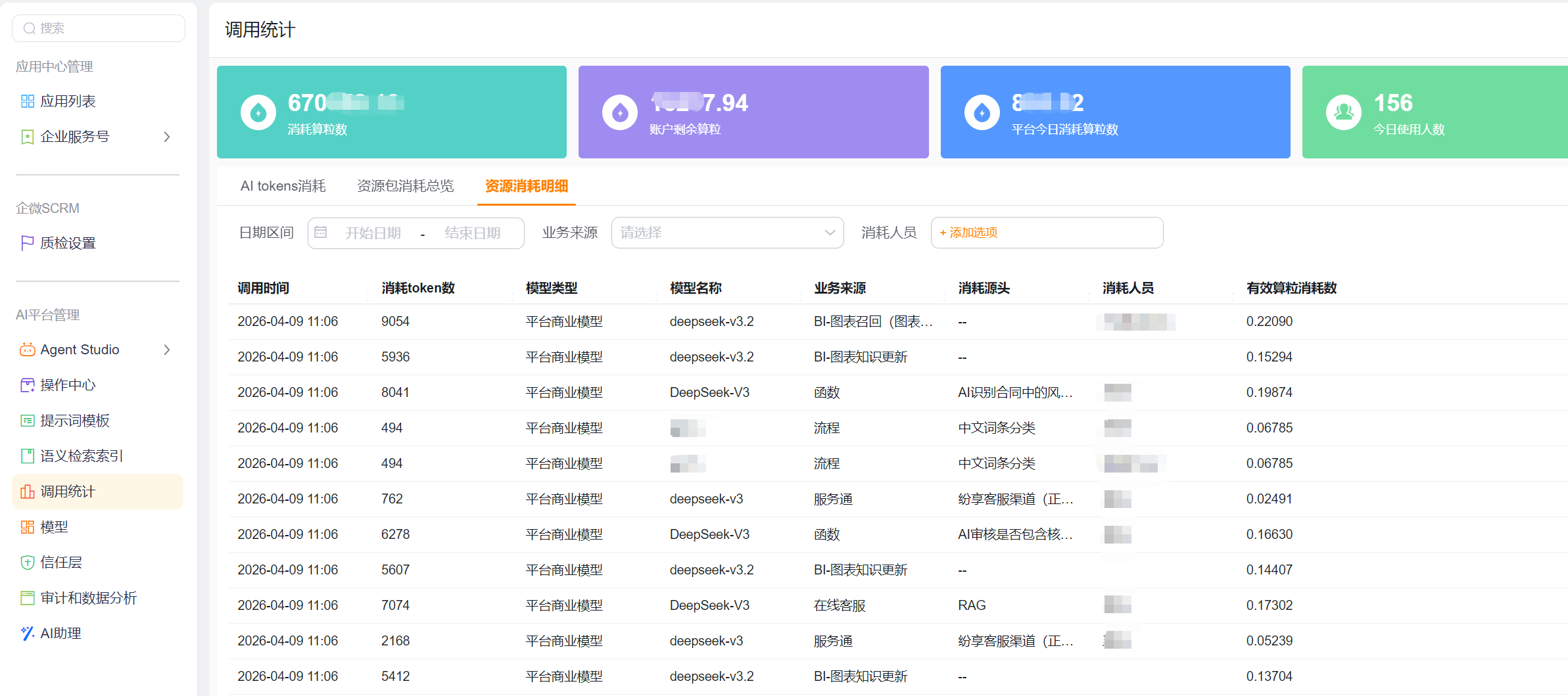
1. 如何控制成本?
| 方法 | 说明 |
| 选择合适的模型 | 简单任务使用低价模型,复杂任务使用高端模型 |
| 控制上下文长度 | 限制历史对话轮数,避免上下文无限增长 |
| 优化提示词与指令 | 精简输入内容,减少无效 token |
| 批量处理 | 合并多个小任务,减少调用次数 |
2. 为什么我的消耗这么快?
| 消耗快原因 | 详细说明 | 解决方案 |
| 使用高端模型 | Deepseek-r1、doubao seed2.0 pro等高端模型价格较高 | 进行a/b test评估是否必须使用高端模型,评估是否有经济模型达到同样效果 |
| 上下文过长 | 历史对话不断累积,每轮输入 token 增加 | 定期重置会话,控制上下文长度 |
| 频繁调用 | 高频调用导致累计消耗增加 | 合并任务,减少调用次数 |
| 多轮推理循环 | 即使简单任务也会触发多次"思考 → 行动 → 观察"循环,每轮都注入大量提示词与工具定义 | 精简工具挂载,只保留当前任务所需工具;同时根据任务复杂度优化指令,避免AI进行不不要的动作规划和执行 |