下面将带您了解使用预测生成器建立预测模型解决业务实际需求的六个步骤。
第 1 步:定义用例
精准的预测和分析是提升业绩的关键。以下是一些通过预测模型可以显著改善的实际业务场景:
- 销售线索转化评分:通过分析销售线索的转化过程,预测模型可以帮助识别那些最有可能转化为商机的线索。这不仅提高了转化率,还优化了资源分配,确保团队将精力集中在最有潜力的线索上。
- 潜在客户管理优化:预测模型能够分析潜在客户的行为和偏好,预测他们转化为订单的可能性。这样,销售团队可以更有效地管理潜在客户关系,减少无效跟进,提高转化效率。
- 商机转化率增强:在商机阶段,预测模型可以预测订单成交的可能性,帮助团队识别关键的成交障碍。通过针对性的策略调整,可以提高商机的成交率,减少资源浪费。
第 2 步:生成训练数据集
预测生成器支持创建数据集,并基于数据集训练预测模型。
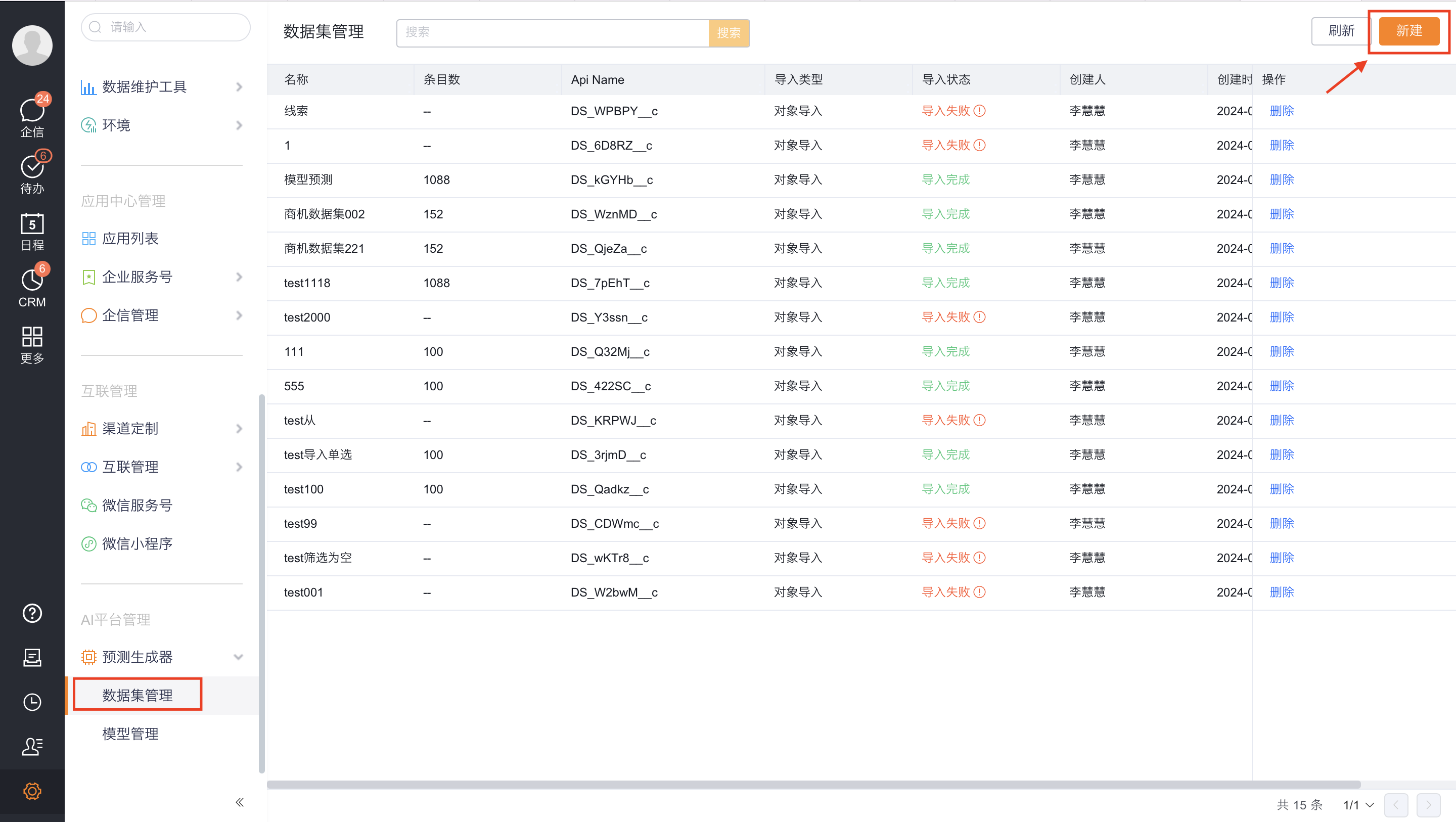
数据集管理入口: 设置/AI平台管理/预测生成器/数据集管理
功能按钮:
- 新建:点击【新建】按钮,可新建数据集。
- 删除:可删除不使用数据集,删除后,模型训练时将不可使用该数据集。
新建数据集的步骤为:
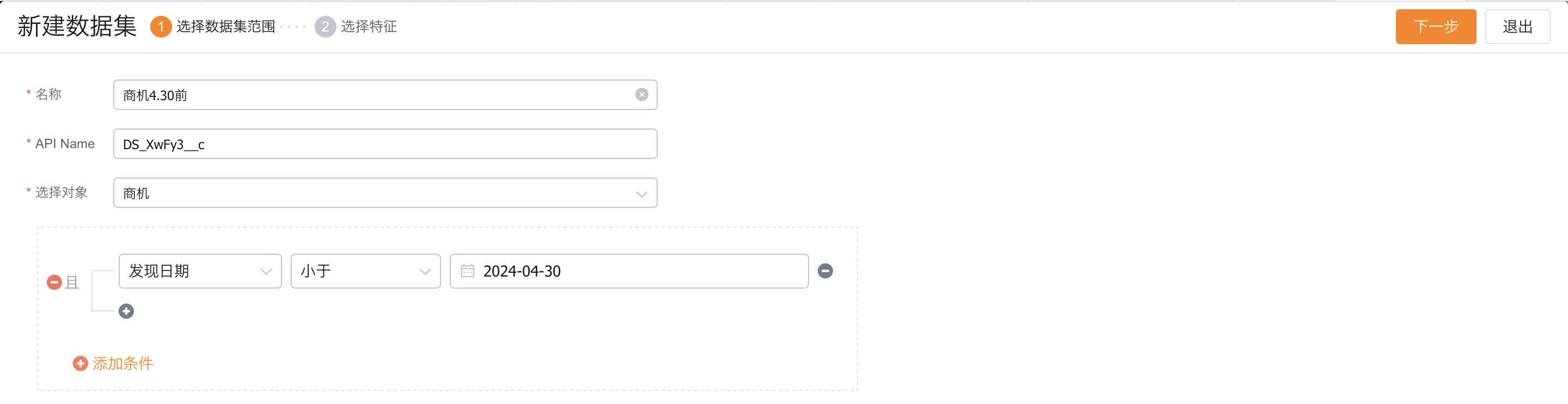
1. 选择数据集范围:
- 支持选择所有预置对象以及自定义对象;
- 增加数据集过滤条件,对对象数据进行细分,例如:以时间范围 ,生成一份三个月以前的商机数据集。
注意:在导入数据集时,由于近期数据还未跟进完成,无法确定近期商机数据对应标签(赢单/输单),因此,在尽量不要选择近期数据训练模型。
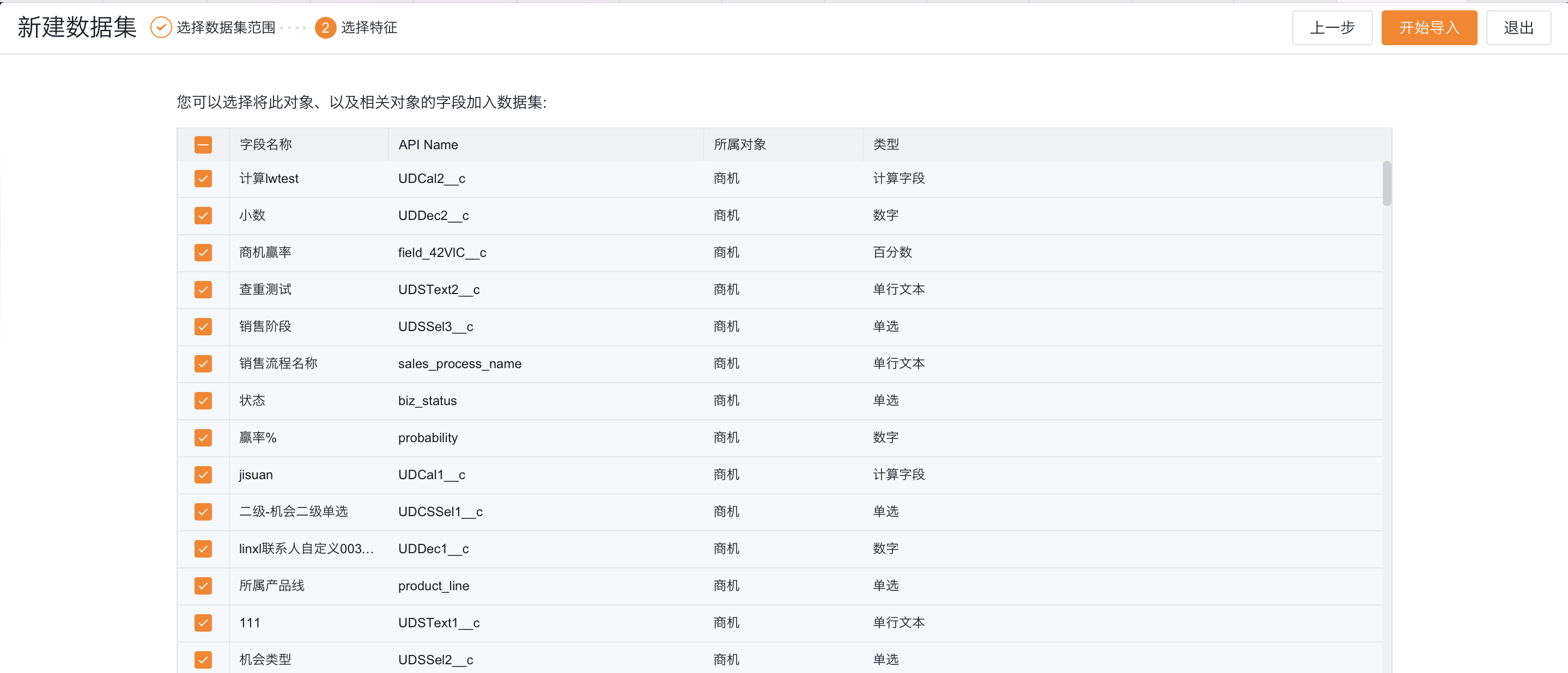
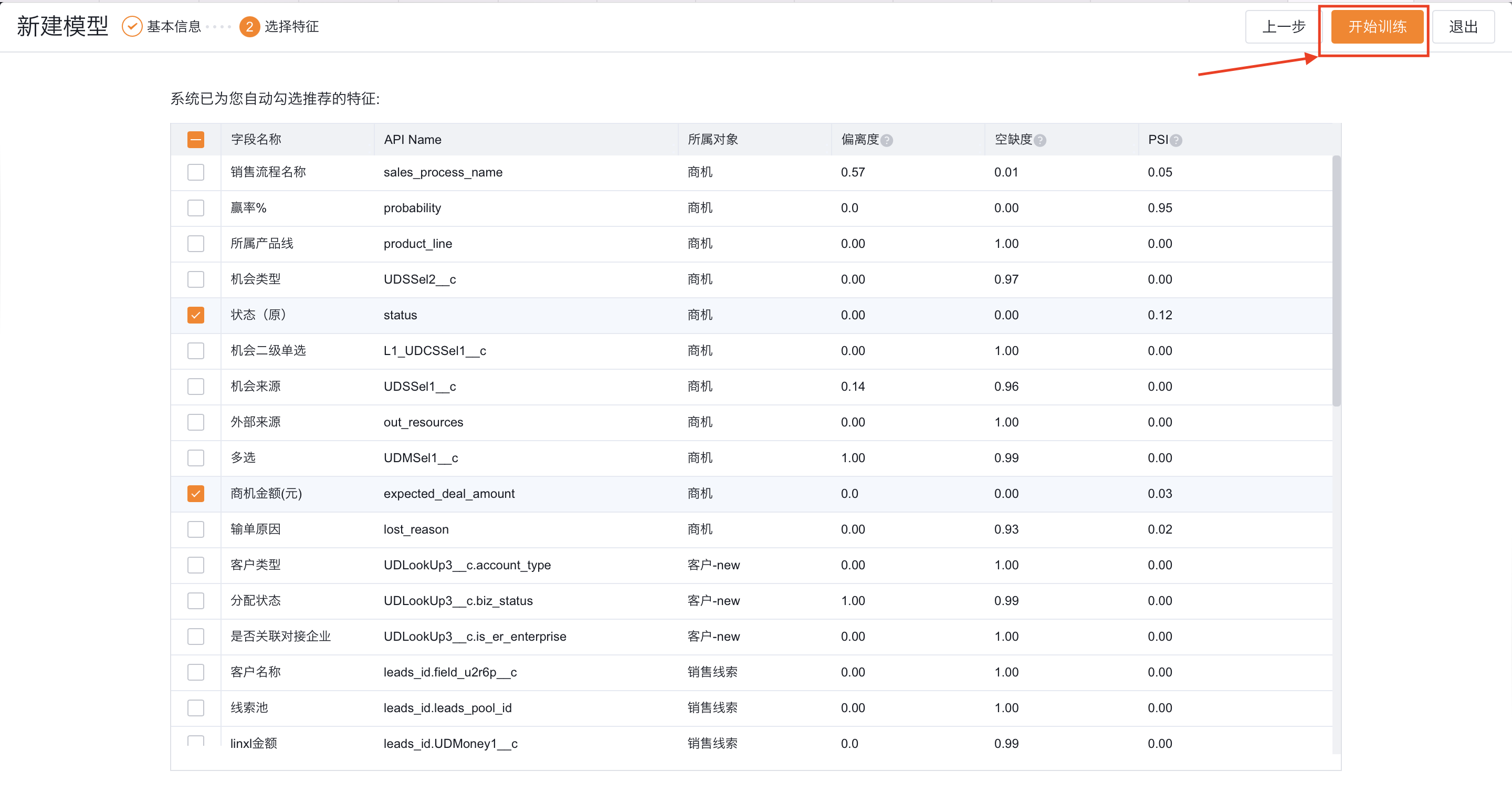
2. 选择特征:
- 选择业务对象字段加入数据集;
- 数据集最少选择3个特征,最多选择100个特征;
第 3 步:创建预测模型
预测生成器可以处理以下类型的预测:
- 二分类预测(例如:商机是/否赢单)
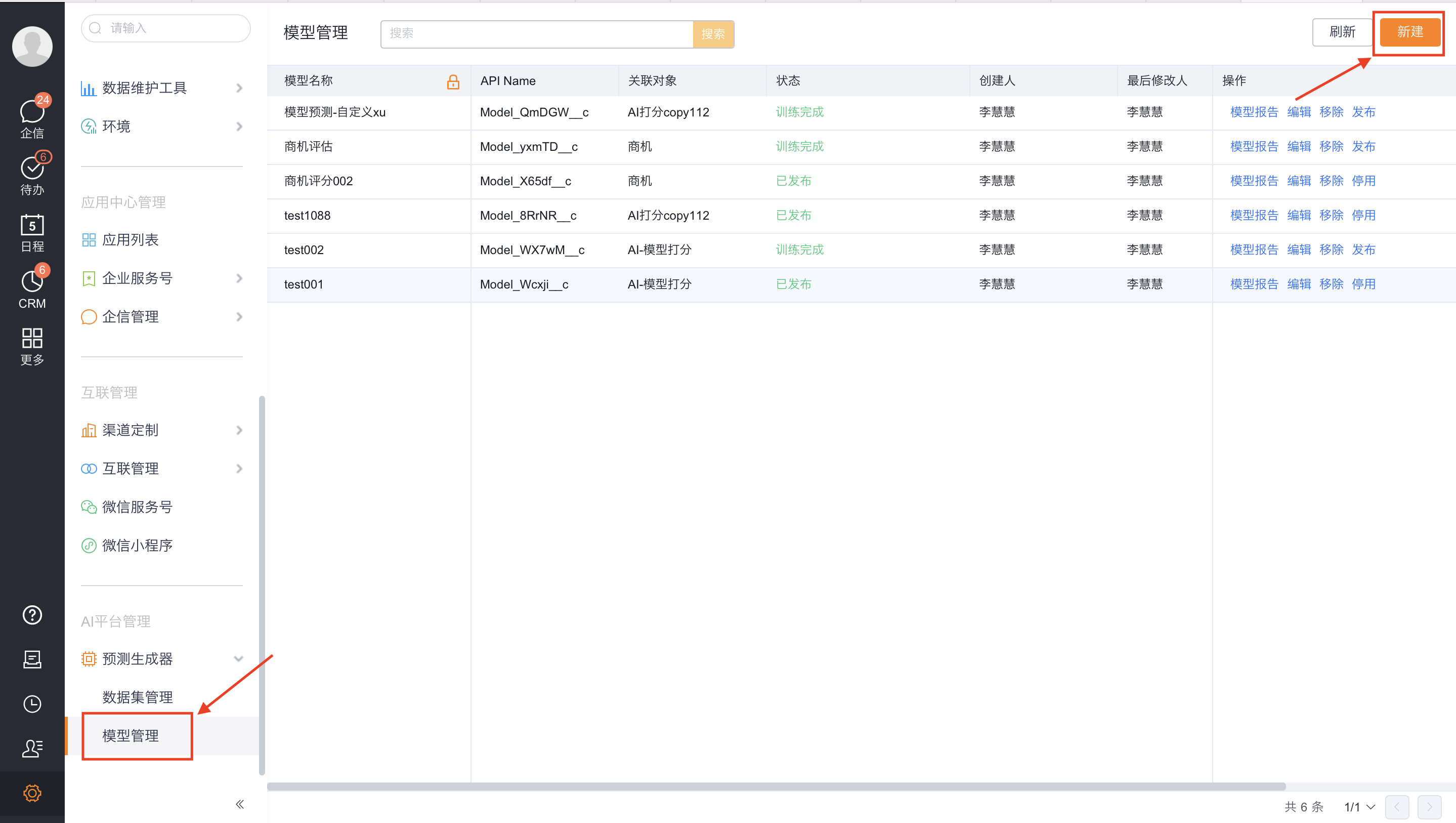
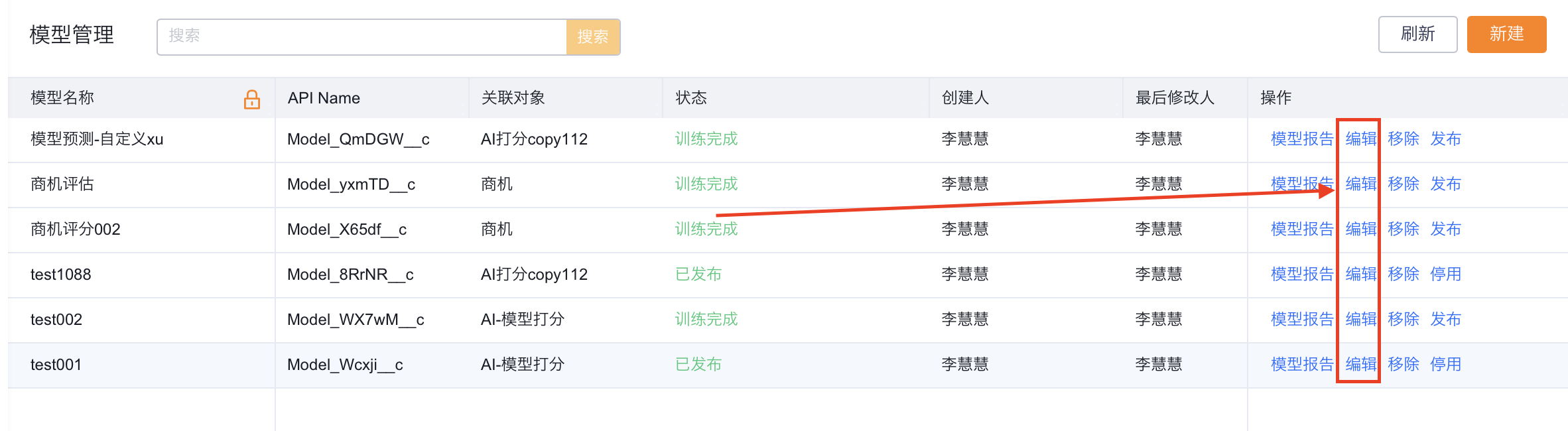
模型管理入口: 设置/AI平台管理/预测生成器/模型管理;
功能按钮:
- 新建:点击【新建】按钮可新建预测模型。
- 模型报告:点击进入模型报告后可查看模型表现、以及模型设置,并可进行模型重训。
- 编辑:点击编辑后可以替换模型特征进行模型重训。
- 移除:移除模型后,已部署该模型的前端模型预测组件将失效,移除前请将该模型与组件解绑。
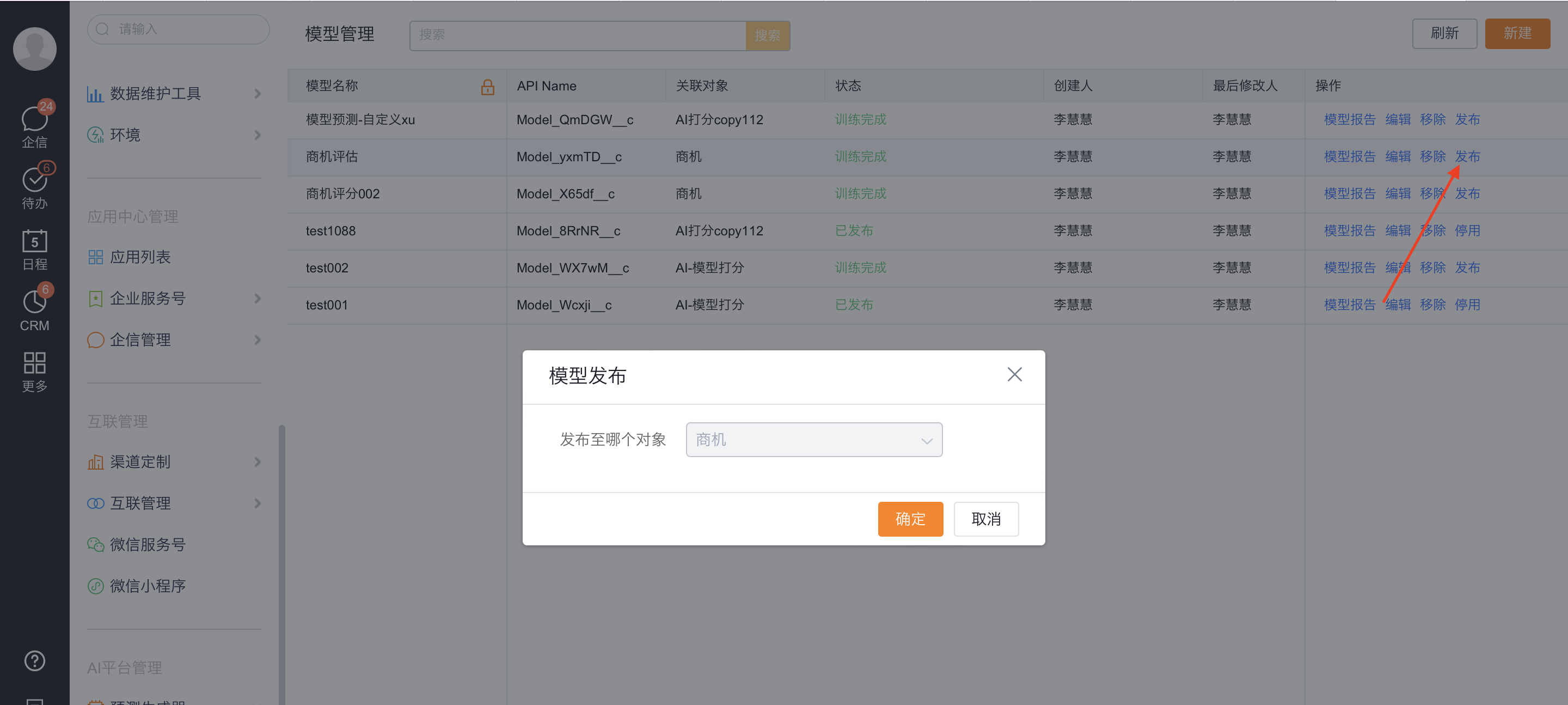
- 发布:可发布训练完成状态模型,发布后可在预测模型组件中部署该模型。
- 停用:停用已发布状态模型,停用后将不可使用。
新建预测模型的步骤为:
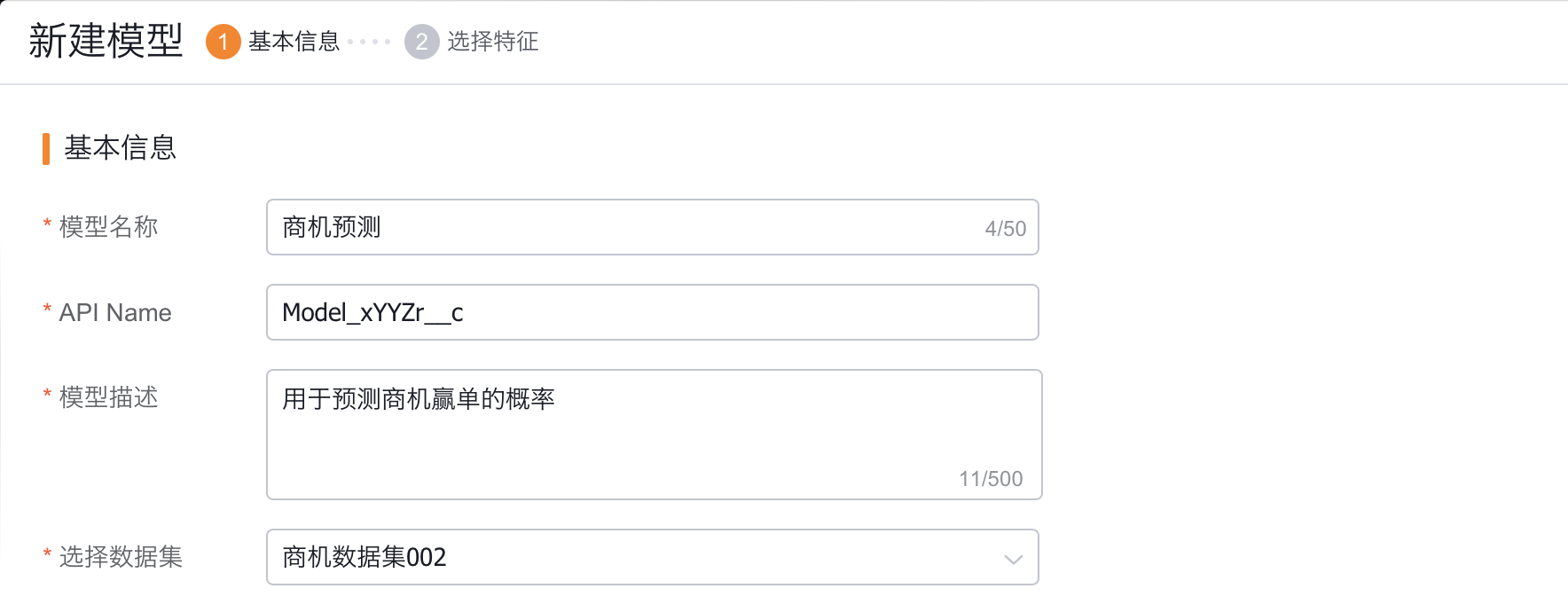
1. 设置模型基础信息
- 模型名称:输入框,最多支持50字符;
- 模型描述:长文本,支持500字符;
- 选择数据集:单选下拉选择已导入成功数据集;
2. 数据集标注。
目标字段:从数据集中的字段中,选择要预测的值,仅支持类型为【单选】的字段;例如:若要预测商机赢单概率,则将商机对象的状态字段设置为目标字段。
期望字段值:目标字段中的某个枚举值,用于将符合该期望值的目标字段标记为正样本;例如,若要预测商机赢单概率,则将赢单状态的商机标注为正样本,期望字段值选择赢单即可。

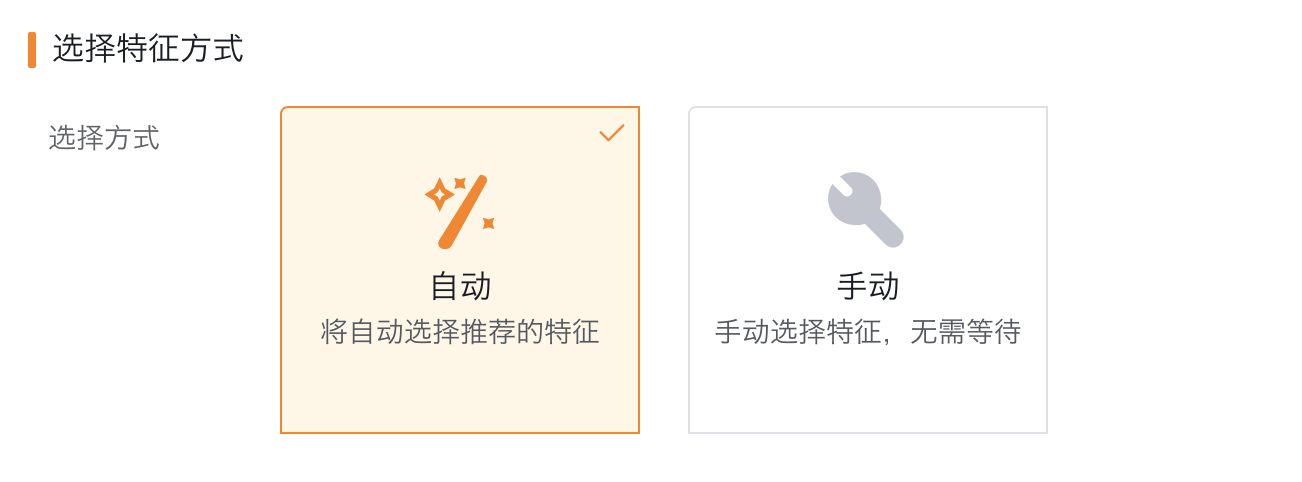
3. 选择特征方式
支持选择【自动】【手动】两种,默认选中自动;
- 自动:选择自动后,系统会自动进行预先进行一轮模型推理,并基于模型自动推荐适合的字段,字段会自动选择12个特征,用户可再自行调整。
- 手动:点击后,系统会直接跳到特征选择页面,默认为空,用户可自行选择,特征选择至少3条,最多30条。
为了降低特征噪声,提高模型预测准确率,我们总结了以下特征筛选原则以供参考:
特征筛选的原则:
- 去除空缺太高的字段,推荐选择空缺率<50%的字段;
- 去除信息过于分散的字段,例如 id , 或一些每个数据都独特的字段如备注);
- 去除在目标变量确认之后才填写的数据 ,例如商机阶段和失败原因字段;
- 去除PSI过大的值,PSI表示字段值分布在不同时期的变化,例如2022年的线索20%转换,而2023年的线索90%都转换,说明此类字段的PSI较大;推荐使用<25%的字段
- 去除偏离值较大的值,偏离值表示字段"个例"的情况有多少,例如“所属地区在北京”占比90%以上;推荐偏离值<50%的字段。
第 4 步:模型训练与模型迭代
一般来说,预测质量越高越好,但如果预测质量太高(大于 95%),则可能是因为您的模型存在一个常见问题,即标签泄漏。
标签泄漏:
是指在训练模型时不小心使用了未来信息(即在预测时不应该可用的信息),这会导致模型过度拟合,从而在实际应用中表现不佳。
例如,客户创建模型来预测哪些商机可能会输单时,因为模型特征选择了一个名为“输单原因”的字段。这个字段是一个泄漏源,因为这些信息在商机预测时不必填写,而只有在输单后,当结果已知时才会填写输单原因。
根据此分析,您很可能需要进行一些迭代并调整您的预测。
模型表现异常常见的调整包括:
- 模型预测得分偏高时:字模型报告/模型设置中查看各特征表现,手动删除相关度极高的特征,即是在预测结果之后填写的特征值(通常是泄漏字段),重训模型。
- 模型预测得分偏低时:通过替换特征,去掉空缺值过高,偏离值过高,PSI过大的特征,选择特征表现更优秀的特征字段。
模型重训入口:
- 模型管理/编辑
- 模型管理/模型报告/训练模型

第 5 步:部署并使用你的预测模型
-
对预测模型表现满意后,点击发布。发布后,模型将支持部署至模型预测组件中。
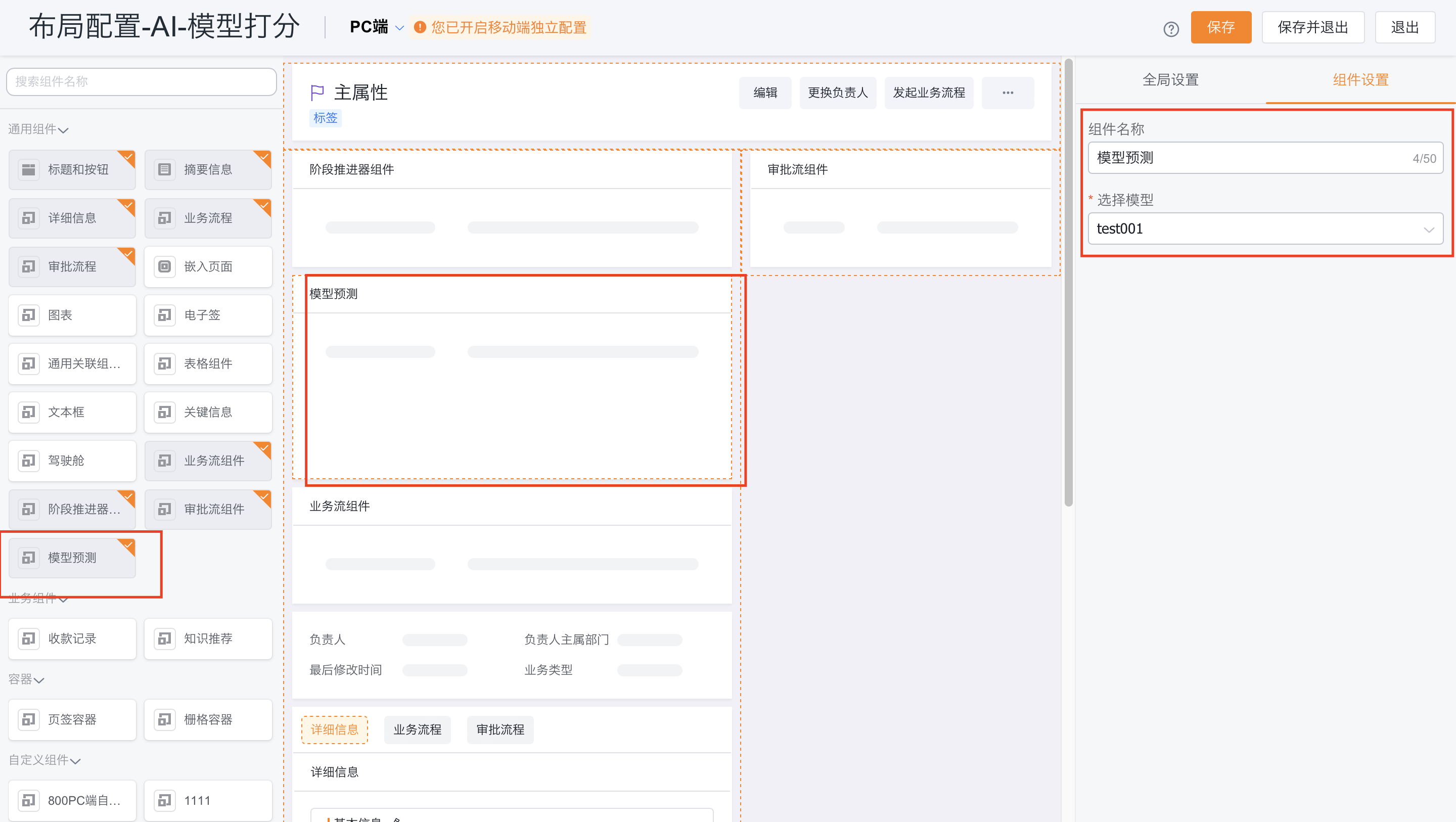
-
将模型预测组件添加到对象详情页面,这样您就可以看到影响每个特定预测的最重要的预测因素。当销售跟进每个线索时,将为销售人员提供有用的信息,通过优化减分项来促成赢单。